이전 게시글 스프링 부트 2
[스프링 부트] 스프링 부트 2
이전 게시글 스프링 부트 1 https://hoozy.tistory.com/entry/%EC%8A%A4%ED%94%84%EB%A7%81-%EB%B6%80%ED%8A%B8-%EC%8A%A4%ED%94%84%EB%A7%81-%EB%B6%80%ED%8A%B8-1 카테고리 : Spring Boot Spring Security 인증(Authentication) : 해당 사용자가 본
hoozy.tistory.com
카테고리 : Spring Boot
Spring Cloud
- MSA 구성을 지원하는 스프링 부트 기반의 프레임워크이다.
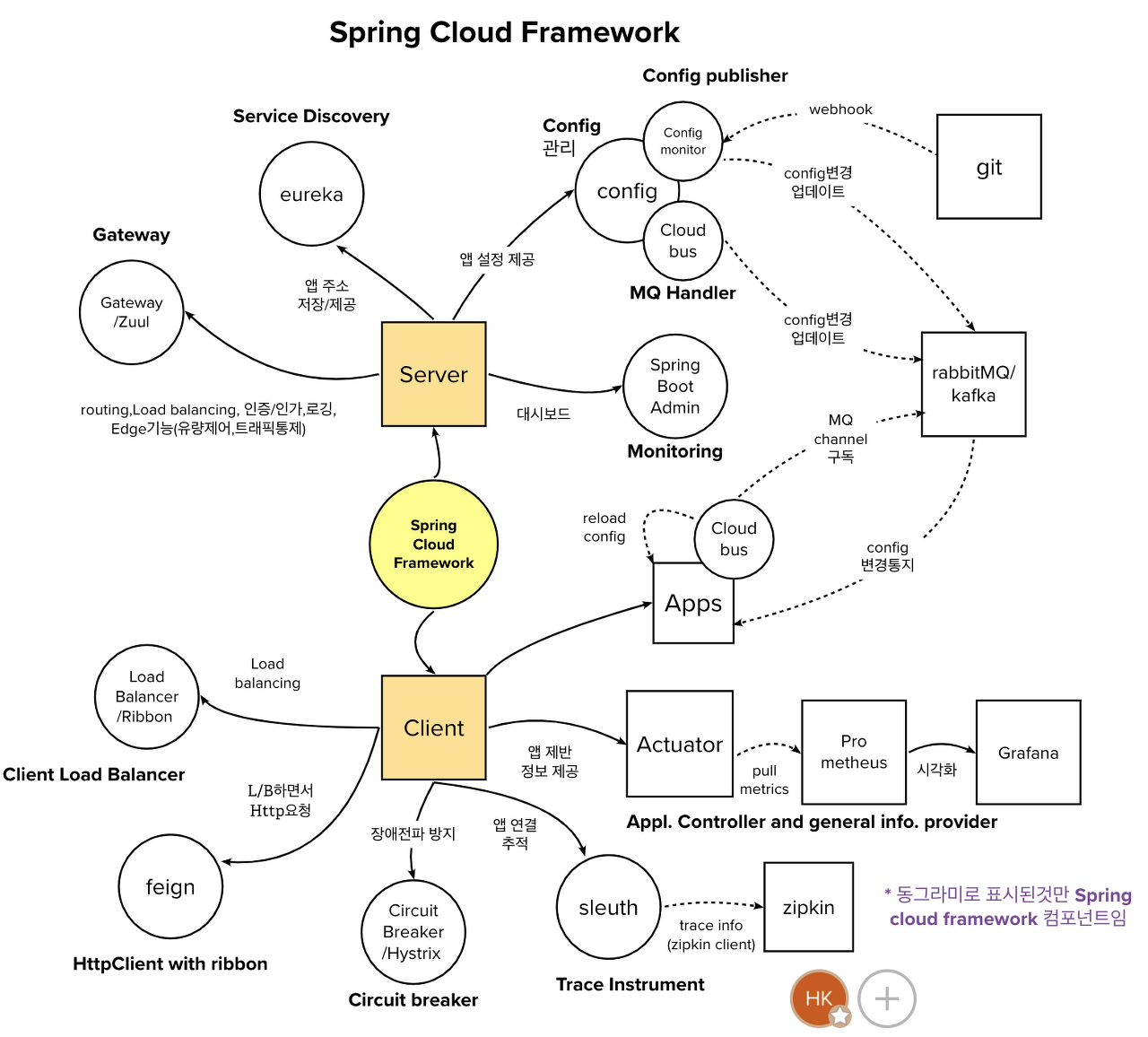
- 위 이미지에서 동그라미로 표시된 것만 Spring Cloud Framework의 컴포넌트이다.
Spring Cloud 의 컴포넌트 종류
- 마이크로 서비스들의 정보를 기록해둘 수 있도록 도와주는 Eureka
- 마이크로 서비스들 사이의 통신을 비동기적으로 도와주는 메세지 큐 RabbitMQ, Kafka 등
- API 게이트웨이 역할로 라우팅을 수행할 Zuul, Spring Cloud Gateway
- 환경설정을 함께 관리하기 위한 Spring Config.
- 로드밸런서가 되어줄 Ribbon.
- 더 효과적인 통신을 위한 Feign
- 트레이싱에 쓰이는 Sleuth 와 zipkin.
아래에서 Eureka, kafka, Spring Cloud Gateway, Spring Config, Sleuth 를 알아보겠습니다.
LB (Load Balancer) -> 로드 밸런서
- 만약 회사 서버 이용자 수가 1억명인데 서버가 1개라면, 못 버틸것이다.
- 따라서 회사에서는 서버를 엄청나게 많이 준비하고 있다. 이때 많은 여러 대의 서버에 트래픽을 골고루 분산하기 위해 배분해주는 기술이 필요하다. 이 때 이용되는 것이 LB이다.
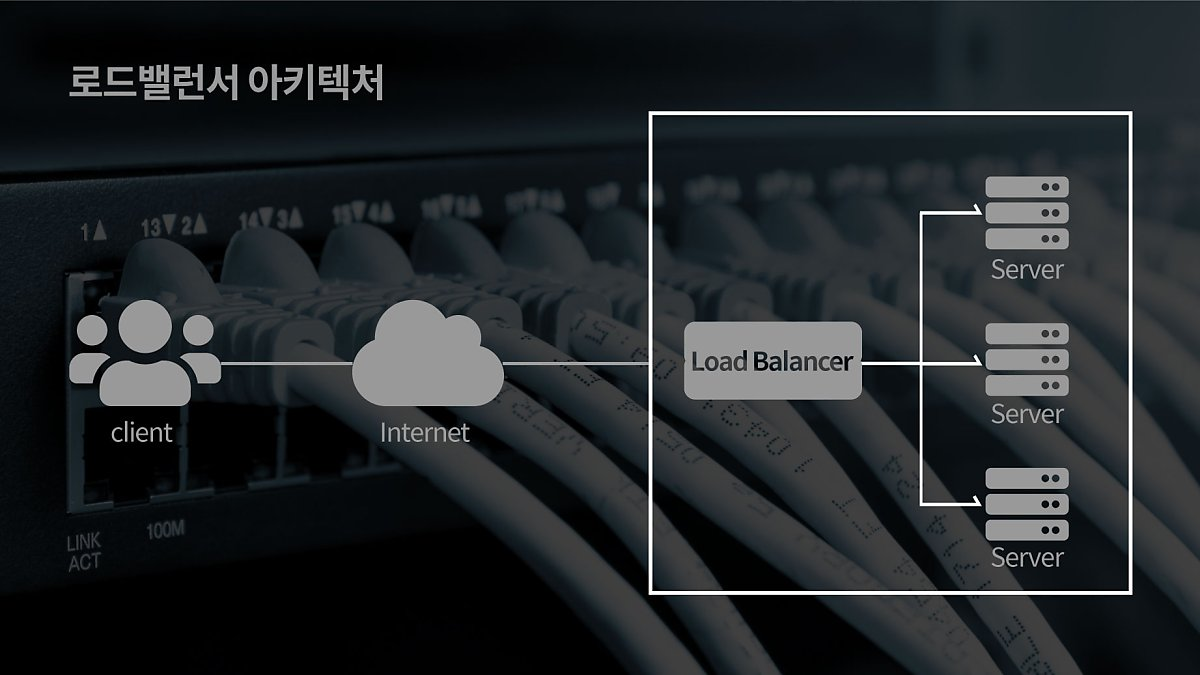
- LB는 MSA의 각 모듈에 대한 연결 정보(ip, port, hostname)를 알고 있다. 이를 사용해 여러 서버를 연결하는 것이다. 우리는 각 모듈의 연결 정보를 LB에 등록해야 한다.
- 하지만 CI/CD를 수행하면서 각 모듈은 계속해서 업그레이드 된다. 그 과정을 통하면서 연결 정보가 바뀌게 된다. 그럼 그때마다 LB에 새롭게 등록해야 한다. 이 문제점을 보완한게 Eureka이다.
Eureka (유레카)
- Eureka는 Neflix에서 제공한 MSA를 위한 클라우드 오픈 소스이다. 즉, LB와 Middle-tier server에 에러 대응을 위한 Rest 기반 서비스이다.
- 위에서 언급한 LB에 연결 정보 등록에 대한 문제점과 에러 처리를 유연하게 하기위한 기술이다. Eureka는 등록과 해지를 곧바로 적용할 수 있게 도와준다.
- Discovery : 다른 서비스의 연결 정보를 찾는 것.
- Registry : 서비스의 연결 정보를 등록하는 것.
흐름 예시
- Eureka Client 서비스가 시작 될 때 Eureka Server에 자신의 정보를 등록한다.
- Eureka Client는 Eureka Server로 부터 다른 Client의 연결정보가 등록되어 있는 Registry를 받고 자신의 Local에 저장하게 된다.
- 30초 마다 Eureka Server로 부터 변경 사항을 갱신받는다.
- 30초 마다 ping을 통하여 자신이 동작하고 있다는 신호를 보낸다. 신호를 보내지 못하면 Eureka Server가 보내지 못한 Client를 Registry에서 제외시킨다.
- 위의 흐름에서 살펴볼 수 있듯이, 모든 서비스 모듈이 스스로 유기적으로 상호작용하는 기술이 Eureka이다.
- #-> (Eureka가 없으면 전부 직접 설정해주어야 한다.. 연결 정보 수정하고.. 등록하고..)
Eureka 구성요소
- Eureka Client
- 각각의 서비스에 해당하는 모듈이라고 생각하면 된다.
- Eureka Client는 자기 스스로 Eureka Server에 등록한다.
- Eureka Client는 연결 정보를 Eureka Server에 등록한다.
- Eureka Client는 Eureka Server로 부터 저장된 Registry 정보를 수신한다. 그리고 자신의 Local에 저장한다.
- Eureka Client는 Eureka Server에게 받은 Registry를 통하여 다른 Clent의 정보를 알 수 있다.
- Eureka Client는 처음 모든 정보를 Local에 저장하고 30초 마다 변경도니 정보를 Eureka Server로 요청한다.
- Eureka Server
- Eureka Client를 관리하는 서버이다.
- Eureka Server는 Eureka Client의 정보를 Registry에 등록한다.
- Eureka Server는 Eureka Client의 Heartbeat를 수신하여 해당 Client가 수행 중임을 안다.
- Heartbeat가 정상적으로 수신되지 않은 경우 Server는 Client가 수행 중이지 않다고 판단하여 해당 Client 정보를 Registry에서 삭제한다.
- HeartBeat : 대기중인 메시지가 없는 경우에 주기적으로 전송되는 시스템 메시지이다. -> 송신 응용 프로그램이 잘 돌아가고 있는지를 확인하는 용도.
kafka
- Apache Kafka는 고성능 데이터 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 오픈 소스 '분산 이벤트 스트리밍 플랫폼'이다.
- 이벤트 스트리밍 : 인체의 중추 신경계에 해당하는 디지털 처리 방식이다.
- 비즈니스가 점점 더 소프트웨어화, 자동화되는 'always-on' 세상을 위한 기술 기반이다.
이벤트 스트리밍 플랫폼
- kafka는 세 가지 주요 기능을 결합하여 end-to-end 이벤트 스트리밍을 구현할 수 있다.
- 이벤트 스트림을 지속적으로 발행(publish-write), 구독(subscribe-read) 한다.
- 이벤트 스트림을 원하는 만큼 내구성 있고 안정적으로 저장(store) 한다. -> KafkaCluster(broker)
- 이벤트 스트림 을 발생 시 또는 소급하여 처리(Process) 한다.
- 그리고 이 모든 기능은 분산되고 확장성이 뛰어나고 탄력적이며 내결함성이 있으며 안전한 방식으로 제공된다. Kafka는 베어메탈 하드웨어, 가상 머신, 컨테이너, 온프레미스 및 클라우드에 배포할 수 있다. Kafka 환경을 자가 관리하거나 다양한 공급업체에서 제공하는 완전 관리형 서비스를 사용할 수 있다.
메시지 큐
- 메시지 지향 미들웨어는 비동기 메시지를 사용하는 각각의 응용프로그램 사이의 데이터 송수신을 의미하고, 이를 구현한 시스템을 메시지큐(Message Queue:MQ)라 한다.
- Kafka는 이벤트 스트리밍 플랫폼으로서 여러가지 역할을 할 수 있고 MQ처럼 메시지 브로커 역할을 할 수 있도록 구현하여 사용할 수도 있으며 기존 범용 메시지브로커들과 비교했을때 아래와 같은 특징을 가진다.
- 대용량의 실시간 로그 처리에 특화되어 TPS가 우수하다. -> 고성능
- 분산 처리에 효과적으로 설계 되어 병렬처리와 확장(Scaleout), 고가용성(HA) 용이 -> 클러스터링
- 발행/구독(Publish-Subscribe) 모델 ( Push-Pull 구조 )
- 메시지를 받기를 원하는 컨슈머가 해당 토픽(topic)을 구독함으로써 메시지를 읽어 오는 구조
- 기존에 퍼블리셔나 브로커 중심적인 브로커 메시지와 달리 똑똑한 컨슈머 중심
- 브로커의 역할이 줄어들기 때문에 좋은 성능을 기대할 수 있음
- 파일 시스템에 메시지를 저장함으로써 영속성(durability)이 보장
- 장애시 데이터 유실 복구 가능
- 메시지가 많이 쌓여도 성능이 크게 저하되지 않음
- 대규모 처리를 위한 batch 작업 용이
kafka의 주요 개념 및 용어
- KafkaCluster : 카프카의 브로커들의 모임. Kafka는 확장성과 고가용성을 위하여 broker들이 클러스터로 구성
- Broker : 각각의 카프카 서버, 동일 노드에 여러 브로커를 띄울 수 있다.
- Zookeeper : 카프카 클러스터 정보 및 분산처리 관리 등 메타데이터 저장. 카프카를 띄우기 위해 반드시 실행되어야 함(곧 카프카 클러스터와 통합 예정)
- Producer : 메시지(이벤트)를 발행하여 생산(Wirte) 하는 주체
- Consumer : 메시지(이벤트)를 구독하여 소비(Read) 하는 주체
토픽, 파티션, 오프셋
- kafka에 저장되는 메시지는 topic으로 분류, topic은 여러 개의 patition으로 나뉜다.
- Topic : 메시지를 구분하는 단위
- 파일시스템의 폴더, 메일함과 유사함 ex) 주문용 토픽, 결제용 토픽 등
- Partition : 메세지를 저장하는 물리적인 파일
- 한 개의 토픽은 한 개 이상의 파티션으로 구성됨
- 파티션은 메시지 추가만 가능한 파일(append-only)
- offset : 파티션내 각 메시지의 저장된 상대적 위치
- 프로듀서가 넣은 메시지는 파티션의 맨 뒤에 추가 (Queue)
- 컨슈머는 오프셋 기준으로 마지막 커밋 시점부터 메시지를 순서대로 읽어서 처리함
- 파티션의 메시지 파일은 처리 후에도 계속 저장되어 있며 설정에 따라 일정시간 뒤 삭제됨
프로듀서, 컨슈머
- Producer: 메시지(이벤트)를 발행하여 생산(Wirte) 하는 주체
- 프로듀서는 메시지 전송시 토픽을 지정
- 파티션은 라운드로빈 방식 혹은 파티션 번호를 지정하여 넣을 수 있음
- 같은 키를 갖는 메시지는 같은 파티션에 저장 되며 순서 유지
- Consumer : 메시지(이벤트)를 구독하며 소비(Read)하는 주체
- Consumer Group
- 메시지를 소비하는 컨슈머들의 논리적 그룹
- Topic의 파티션은 컨슈머그룹과 1:N 매칭 관계로 동일 그룹내 한 개의 컨슈머만 연결가능 하다.
- 이로써 파티션의 메시지는 순서대로 처리되도록 보장
- 특정 컨슈머에 문제가 생겼을때 Fail over를 통한 리밸런싱 가능
- 보통 파티션과 컨슈머는 1:1이 best practice로 봄
- Consumer Group
kafka를 사용하는 이유
- 고성능
- 다중 프로듀서, 다중 컨슈머가 상호 간섭없이 메시지를 쓰고 읽어서 처리
- 디스크 기반의 이벤트 보존
- 지속해서 보존 가능, 데이터 유실 위험이 적고 컨슈머가 항상 안떠있어도 됨.
- 장애 발생시 유실 복구 가능(재처리)
- 파티션 파일은 OS 페이지 캐시를 통해 IO를 메모리에서 처리하여 성능이 유리
- Zero Copy를 통해 디스크 버퍼에서 네트워크 버퍼로 직접 데이터 복사
- 브로커가 하는일이 비교적 단순 - 똑똑한 컨슈머
- 브로커는 컨슈머와 파티션간 맵핑 관리만 하며 성능에 집중
- 메시지 필터, 메시지 재전송과 같은 일은 프로듀서, 컨슈머에 위임
- batch 기능을 제공하여 동시 처리량 증가
- 프로듀서 : 일정 크기만큼 메시지를 모아서 전송
- 컨슈머 : 최소 크키만큼 메시지를 모아서 읽어옴
- 확장성(scale out) : 수평 확장이 쉽게 가능 > 브로커,파티션, 컨슈머 추가
- 고가용성
- Kafka의 topic은 partition이라는 단위로 쪼개어져 클러스터의 각 서버들에 분산되어 저장되고, 고가용성을 위하여 복제(replication) 설정을 할 경우 이 또한 partition 단위로 각 서버들에 분산되어 복제되고 장애가 발생하면 partition 단위로 fail over가 수행된다.
- Replication : 토픽내 파티션의 복제본. replication-factor를 통해 개수를 지정할 수 있다.
- 복제수(replication factor)만큼 파티션의 복제본이 각 브로커에 생김
- 토픽 생성시 복제수를 2로 하면 파티션이 2개가 각각의 브로커에 생김
- leader와 follower로 구성
- 프로듀서&컨슈머는 리더를 통해서만 메시지 처리
- 팔로워는 리더가 속한 브로커에서 메시지를 복제함
- 리더가 속한 브록커가 장애나면 다른 팔로워가 리더가 되어서 처리
API Gateway
- Reserve Proxy 처럼 클라이언트 요청의 앞단에 위치한다. 서버에 들어온 모든 요청들에게 어디로 가야할 지 '라우팅'을 해줄 수 있고 들어오고 나가는 명단을 '로깅' 할 수도 있다.
- 역할
- API 라우팅
- 인증 및 권한 부여
- 속도 제한
- 부하 분산 (로드밸런싱)
- 로깅 (모니터링)
- 오케스트레이션Reserve Proxy
- Proxy Server
- 클라이언트와 서버 사이의 중계기로서 대리로 통신을 수행하는 역할을 한다.
- 클라이언트와 서버가 직접 통신하지 않아서 보안, 트래픽 분산 등 장점이 있다.
- Forward Proxy
- 클라이언트 - 프록시 서버 - 인터넷 - 애플리케이션 서버
- 클라이언트가 서버로 직접 요청하지 않고, 프록시 서버를 이용하기에 서버에서는 클라이언트를 알 수 없다.
- 회사 내부 인트라넷이 대표적인 예시이다.
- 주요 역할은 캐싱, IP 우회, 제한된 사이트 접근이다.
- Reserve Proxy
- 클라이언트 - 인터넷 - 프록시 서버 - 애플리케이션 서버(내부 망)
- Forward Proxy와는 반대로 서버를 숨기는 역할을 한다.
- 주요 역할은 로드 밸런싱, 보안이다.
Spring Cloud Gateway (SCG)
- Gradle
implementation 'org.springframework.cloud:spring-cloud-starter-gateway'- Spring Reactive 환경에 구현된 API Gateway이다.
- API Gateway는 모든 요청이 통과하는 곳이기에 성능이 중요하다. 따라서 Tomcat이 아닌 Netty를 사용하여 non-Blocking 요청 처리를 제공한다.
- Netflix Zuul 2.x도 non-Blocking을 지원하지만, SCG가 스프링과 잘 맞고, 스프링에서도 SCG를 권장한다.
- 또한, Zuul은 Filter로만 동작하고, SCG는 Predicates + Filter를 조합하여 동작하며 비동기 처리에 유리하다.
- 아래 이미지는 SCG의 구조이다.
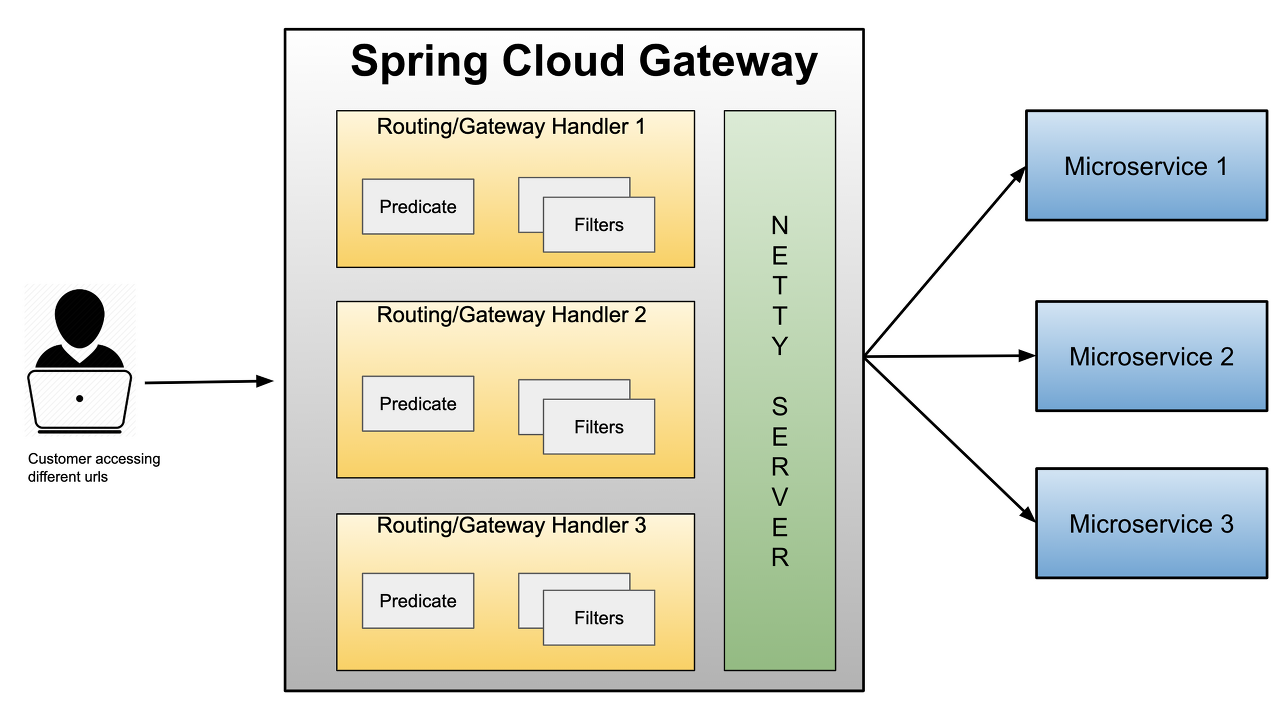
SCG의 3가지 옵션
- Route
- 응답을 보낼 목적지 uri와 필터 항목을 식별하기 위한 ID로 구성되어 있고 라우팅 목적지를 의미한다.
- Predicate
- 요청을 처리하기 전 HTTP 요청이 정의된 조건에 부합하는지 검사하며 Java 8의 Function Predicate 이다.
- Filter
- 게이트웨이에서 받은 요청과 응답을 수정하는 역할로 Spring Framework의 WebFilter 인스턴스이다.
# application.yml 예시 코드
spring:
cloud:
gateway:
default-filters: // 기본 필터
- name: GlobalFilter
agrs:
preLogger: true
postLogger: true
routes:
- id: product-service
uri: lb://PRODUCT-SERVICE
predicates:
- Path=/product/**
filters: // 각 서비스에 적용할 수 있는 내부 서비스 필터
- name: UserFilter
args:
baseMessage: productFilter
preLogger: true
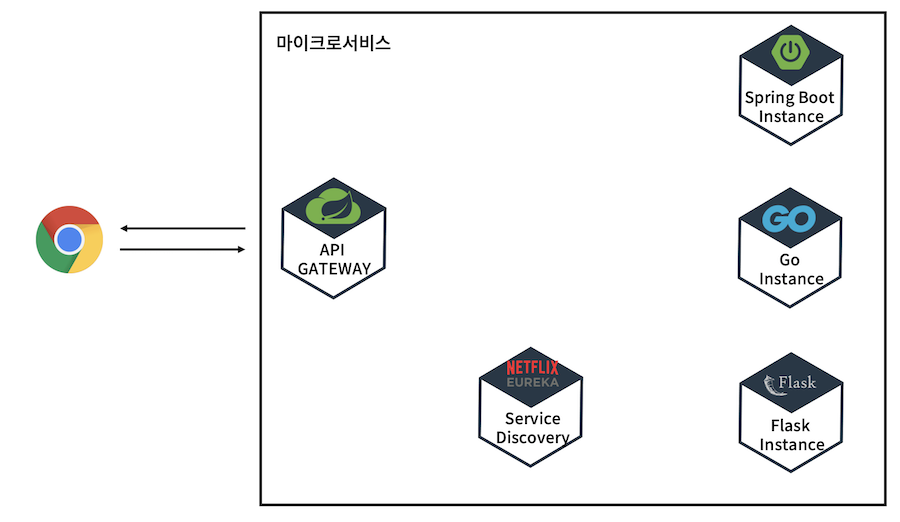
postLogger: trueMSA 구조에서 Eureka를 접목한 SCG 구현
- 유레카만 구현된 서비스의 모습
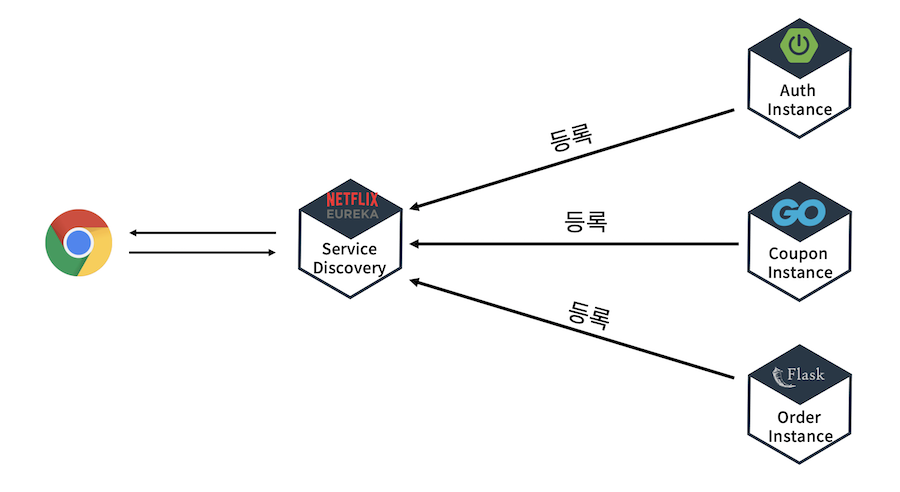
- SCG를 더한 모습
- 여기서 클라이언트 요청 시나리오 모습
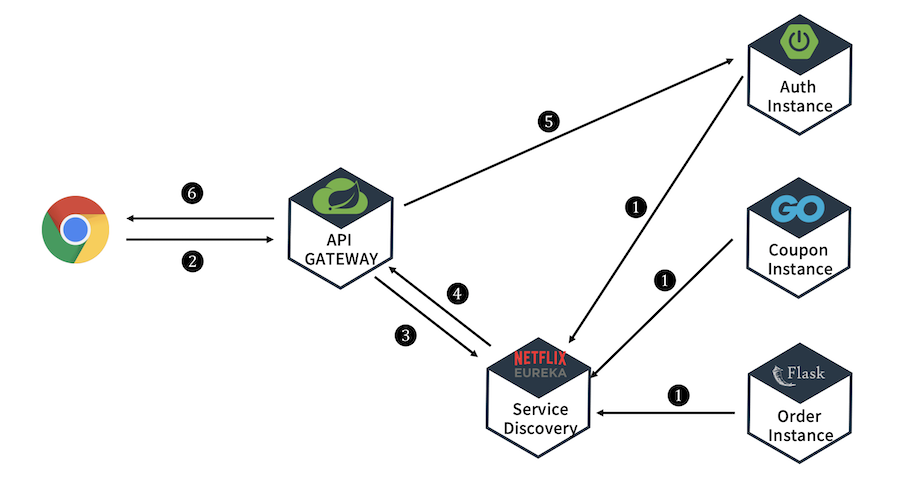
- 각 인스턴스(서비스)를 실행하여 유레카 서버에 등록. -> SCG도 유레카 입장에선 서비스익 때문에 등록해야 한다.
- 클라이언트에서 로그인 요청이 SCG로 들어온다.
- 게이트웨이가 받은 요청을 어떤 서비스에서 해결할 지 디스커버리(유레카)에게 찾는다.
- 유레카가 응답해준다.
- 게이트웨이는 받았던 로그인 요청을 Auth 서비스에게 던진다.
- 최종 결과를 사용자에게 리턴한다.
Spring Cloud Config
- 만약 사용하고자 하는 서비스의 환경설정 값의 수정이 필요한 경우, 해당 어플리케이션은 변경된 환경설정 값을 수정하여 다시 빌드하고 배포를 하는 과정을 거쳐야 하는데요. 만약 환경설정 값의 수정이 자주 일어나거나, 관리해야 할 서비스가 많은 경우 이것은 매우 번거로운 일이 될 수 있다.
- Spring Cloud Config 는 분산 시스템에서 외부화된 설정 정보를 서버 및 클라이언트에게 제공하는 시스템으로 모든 외부 환경설정에 대한 정보들을 관리해주는 '중앙 서버'의 역할을 한다. 주요 기능으로는 서비스의 환경설정 값이 변경되었을 때 다시 빌드하고 배포하는 과정 없이 변경된 설정 값을 반영할 수 있다는 장점이 있다.
- 단점
- Spring Cloud Config에서 외부 설정 파일은 git repository에 저장하여 사용하는 경우가 많은데, git 서버 또는 설정 서버 (config server)에 의한 장애가 전파될 수 있으며, 설정 파일이 여러 곳에 나뉘어져 있고, 제대로 관리가 되지 않는 경우 Spring Cloud Config가 설정 파일을 읽어드리는 우선 순위에 의해 잘못된 정보를 가져오게 될 수도 있다.
- 설정 파일이 존재할 수 있는 위치이며, 1번부터 순서대로 읽어지는데, 나중에 읽어지는 것이 우선 순위가 높다.
- 프로젝트의 application.yml
- 설정 저장소의 application.yml
- 프로젝트의 application-{profile}.yml
- 설정 저장소의 {application name}/{application name}-{profile}
동작 원리
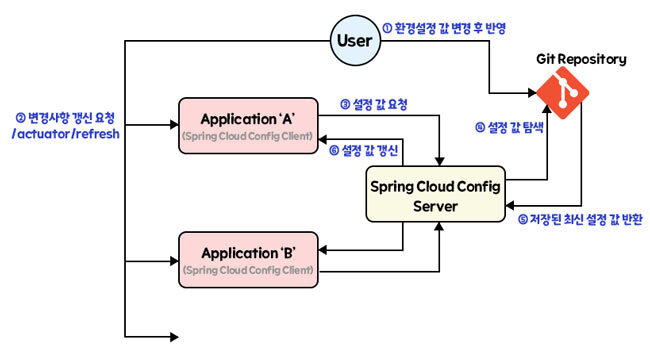
- Spring Cloud Config는 세 가지 부분으로 나눠서 볼 수 있다.
- 핵심이 되는 'Spring Cloud Config Server'와 하나 이상의 'Spring Cloud Config Client', 그리고 설정 파일이 저장되는 'Git Repository(또는 JDBC, REDIS, File System, MySQL 등)'로 나뉘어 진다.
- 동작 방식
- 유저가 환경 설정 값 변경 후 중앙 저장소에 저장.
- Config Client에 변경 사항 갱신 요청 -> /actuator/refresh
- Config Client가 Config Server에게 설정 값을 요청.
- Config Server는 설정 값이 저장된 중앙 저장소(Git Repository 등)를 통해 해당 설정 값을 찾음
- Config Server가 Config Client에게 다시 전달해서 설정 값 갱신.
- 만약 위의 구조에서 Config Server에 연결된 Client의 수가 많고, 해당 Client 들에게 공통적으로 사용되는 설정 값이 변경되었다고 하면, 각각의 Client 모두에 /actuator/refresh 를 호출해야 하는데, 이는 비효율적이고 실수로 호출을 빼먹었을 경우 문제가 발생할 수도 있다. -> 이를 'Spring Cloud Bus'로 해결할 수 있다.
Spring Cloud Bus
- 위의 Config의 문제점 처럼 여러 Client 들에게 공통적으로 사용되는 설정 값이 변경되었다고 하면, 각각의 Client 모두에 /actuator/refresh 요청을 한 번씩 보내는 게 아니라, 한 번에 다 연결된 Client에 모두 refresh 해주는 방법이다.
- 즉, 동적으로 config 변경을 적용하기 위한 MQ(Message Queue) Handler이다.
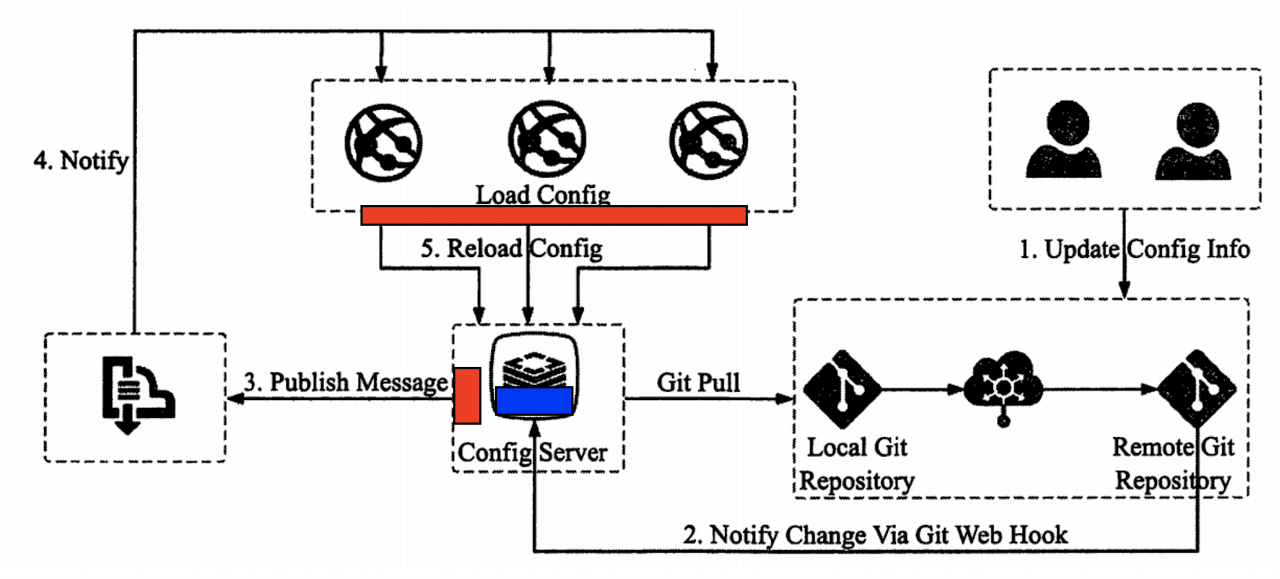
- 위의 그림처럼 Config Server와 마이크로서비스(=Client) 간에 메시지 Queue(rabbitMQ 또는 kafka)를 통해 설정 값을 참조하도록 한다.
- 3가지 기능
- MQ에 Publisher(=Config Server)와 Subscriber(마이크로서비스=Client)를 등록
- Config 변경 정보를 MQ에 전송 (위 이미지 3. Publish Message)
- 각 마이크로서비스에서 Config 동적 반영 (위 이미지 5. Reload Config)
- 동작 순서 -> 빨간색 box가 Spring Cloud Bus, 파란색 box가 Spring Cloud Config Monitor 이다.
- Update Config Info: Git의 설정값이 갱신됨. git repository에서 파일을 직접 변경하거나, git push함
- Notify Change Via Git Web Hook: webhook이 POST로 https://{config server host}/actuator/bus-refresh를 실행함.
사전에 git에서 기본으로 제공하는 webhook에 bus-refresh를 수행하는 프로그램을 등록해야 함
Spring Cloud Config Monitor를 이용할 때는 https://{config server host}/monitor로 등록함(Spring Cloud Config Monitor참조) - Publish Message: config server는 Git에서 변경된 내용을 읽어 MQ에 Publish함
- Notify: MQ는 각 마이크로서비스에 설정값 갱신이 필요함을 통지
- Reload Config: 각 마이크로서비스는 config server를 통해 갱신된 설정값을 읽어 반영함
Sleuth
- 마이크로 서비스로 개발하게 되면 자연스럽게 마이크로 서비스 간에 연결이 많아지고 복잡해진다. 예를 들어 고객이 같은 시간에 제품 3개를 주문했다고 가정해보자. 이때 만약에 중간에 처리가 늦어지거나 중단된다면, 어느 지점이 문제인지 빠르게 찾을 수 있어야 한다.
- Sleuth는 분산된 마이크로 서비스 간에 트래픽의 흐름을 추적할 수 있도록 Trace기록을 로그에 자동 삽입해준다.
- 즉, 분산된 마이크로 서비스 간의 트래픽을 추적하여 문제를 사전에 방지하거나 해결하기 위해 사용한다.
어떻게 추적하는가
- 동일한 트랜잭션에 해당하는 트래픽들에 동일한 Trace ID를 부여하면 된다.
- 위의 구매 트랜잭션에서 모든 트래픽이 동일한 Trace ID를 갖고 있다면 쉽게 추적할 수 있을 것이다. Sleuth를 적용한 후 로깅 라이브러리(Slf4j 등)를 사용하여 로깅하면, 자동으로 로그에 Service 명, Trace ID, Span ID 가 삽입된다.
- Service 명은 설정한 트랜잭션의 이름이고, Trace ID는 트랜잭션의 고유 ID이고, Span ID는 각각 트래픽의 고유 ID이므로 구분이 쉽게 가능하다.
- 또한 위의 Tracing 정보에는 4가지의 timestamp가 있어 소요된 시간까지 측정할 수 있다.
- CS(Client Start) -> SR(Server Received) -> SS(Server Sent) -> CR(Client Received)
참고 자료
https://velog.io/@jkijki12/Eureka%EB%9E%80
https://velog.io/@gowjr207/%EC%8A%A4%ED%94%84%EB%A7%81-%ED%81%B4%EB%9D%BC%EC%9A%B0%EB%93%9C%EB%A5%BC-%EC%84%A4%EB%AA%85%ED%95%B4%EB%B3%B4%EB%8B%A4
https://velog.io/@gowjr207/%EC%8A%A4%ED%94%84%EB%A7%81-%ED%81%B4%EB%9D%BC%EC%9A%B0%EB%93%9C-%EA%B2%8C%EC%9D%B4%ED%8A%B8%EC%9B%A8%EC%9D%B4%EB%A5%BC-%EC%84%A4%EB%AA%85%ED%95%B4%EB%B3%B4%EB%8B%A4
https://hoooon-s.tistory.com/201
https://ifuwanna.tistory.com/487
https://wildeveloperetrain.tistory.com/214
https://happycloud-lee.tistory.com/211
https://happycloud-lee.tistory.com/212
https://happycloud-lee.tistory.com/216
'CS > Spring Boot' 카테고리의 다른 글
| [스프링 부트] 스프링 부트 2 (0) | 2023.04.08 |
|---|---|
| [스프링 부트] 스프링 부트 1 (0) | 2023.04.06 |


댓글