이전 게시글 관계형 DB
https://hoozy.tistory.com/entry/%EB%B0%B1%EC%97%94%EB%93%9C-%EA%B4%80%EA%B3%84%ED%98%95-DB
[백엔드] 관계형 DB
이전 게시글 운영 체제 2 https://hoozy.tistory.com/entry/%EB%B0%B1%EC%97%94%EB%93%9C-%EC%9A%B4%EC%98%81-%EC%B2%B4%EC%A0%9C-2 카테고리 : 데이터베이스 관계형 데이터베이스란 행과 열로 이루어진 각각의 테이블을 고유
hoozy.tistory.com
카테고리 : 데이터베이스
비관계형 데이터베이스란
- 관계형 데이터 모델(RDBMS)을 지양하며 대량의 분산된 데이터를 저장하고 조회하는데 특화되었으며 스키마 없이 사용 가능하거나 느슨한 스키마를 제공하는 데이터베이스 모델이다. -> 관계형 데이터베이스의 한계를 극복하기 위한 데이터베이스의 새로운 형태.
- 특징
- 데이터 간의 관계를 정의하지 않는다.
- RDBMS는 데이터 관계를 외래키 등으로 정의하고 JOIN 연산을 수행할 수 있지만, NoSQL은 JOIN 연산이 불가능하다.
- RDBMS에 비해 대용량의 데이터를 저장할 수 있다.
- 페타바이트 급의 대용량 데이터를 저장할 수 있다.
- 분산형 구조이다.
- 여러 곳의 서버에 데이터를 분산 저장해 특정 서버에 장애가 발생했을 때도 데이터 유실 혹은 서비스 중지가 발생하지 않도록 한다.
- 고정되지 않은 테이블 스키마를 갖는다.
- RDBMS와 달리 테이블의 스키마가 유동적이다. 데이터를 저장하는 컬럼이 각기 다른 이름과 다른 데이터 타입을 갖는 것이 허용된다.
- 데이터 간의 관계를 정의하지 않는다.
- 장점
- RDBMS에 비해 저렴한 비용으로 분산 처리와 병령 처리 가능.
- 비정형 데이터 구조 설계로 설계 비용 감소.
- 빅 데이터 처리에 효과적
- 가변적인 구조로 데이터 저장이 가능
- 데이터 모델의 유여한 변화가 가능
- 단점
- 데이터 업데이트 중 장애가 발생하면 데이터 손실 발생 가능
- 많은 인덱스를 사용하려면 충분한 메모리가 필요. 인덱스 구조가 메모리에 저장.
- 데이터 일관성이 항상 보장되지 않음.
비관계형 데이터베이스 종류
1. Key-Value
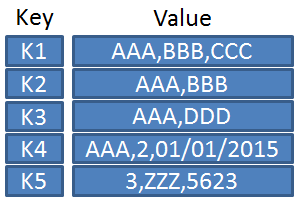
- 기본적인 패턴으로 Key-Value 하나의 묶음(Unique)으로 저장되는 구조로 단순한 구조이기에 빠르며 분산 저장 시 용이하다.
- Key 안에 (Column, Value) 형태로 된 여러 개의 필드, 즉 Column Families 갖는다.
- 주로 Server Config, Session Clustering 등에 사용되고 액세스 속도는 빠르지만, Scan에는 용이하지 않다.
- EX) Redis, Oracle NoSQL DB, VoldeMorte
2. Wide-Column
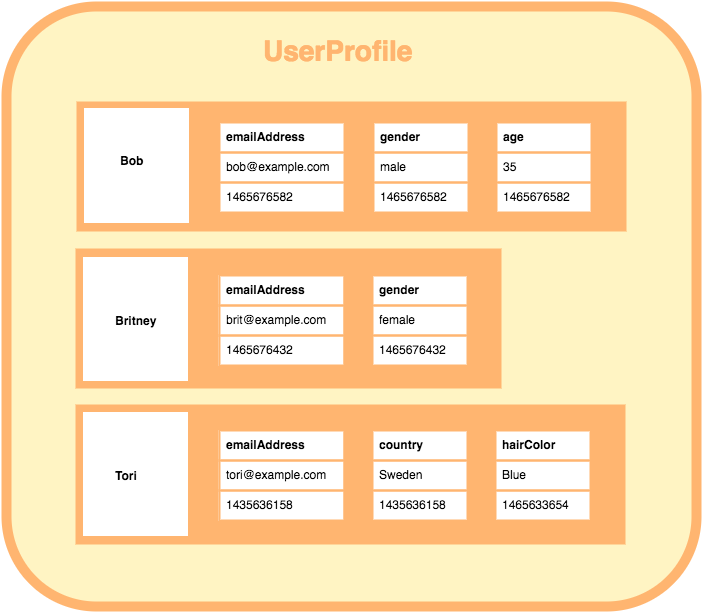
- 행마다 키와 해당 값을 저장할 때마다 각각 다른 값의 다른 수의 스키마를 가질 수 있다.
- 위 그림을 참고하면 사용자의 이름(key)에 해당하는 값에 스키마들이 각각 다름을 볼 수 있다.
- 이러한 구조를 갖는 wide column database는 대량의 데이터의 압축, 분산 처리, 집계 쿼리 (sum, count, avg) 및 쿼리 동작 속도 그리고 확장성이 뛰어난 것이 그 대표적 특징이다.
- EX) Hbase, GoogleBigTable, Vertica
3. Document
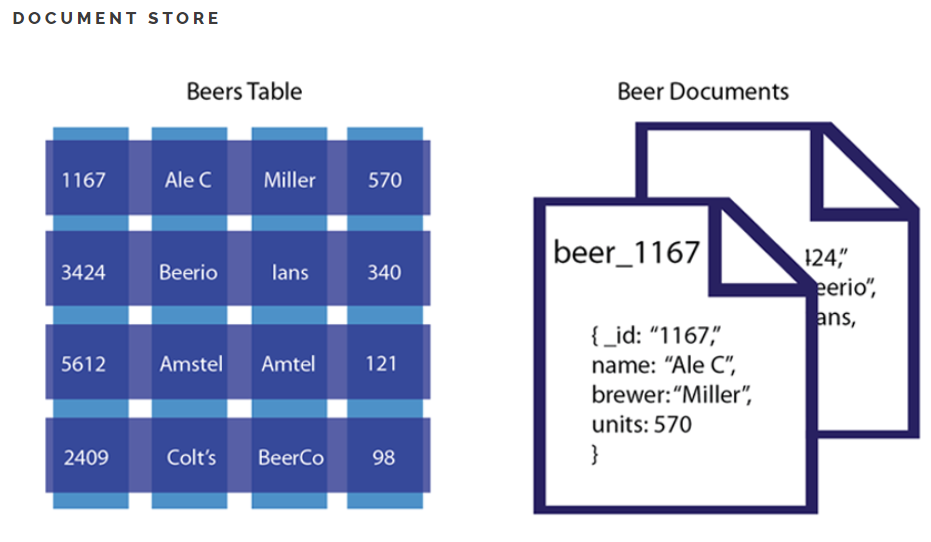
- 테이블의 스키마가 유동적, 즉 레코드마다 각각 다른 스키마를 가질 수 있다.
- 보통 XML, JSON과 같은 DOCUMENT를 이용해 레코드를 저장한다. 트리형 구조로 레코드를 저장하거나 검색하는데 효과적이다.
- EX) MongoDB, CouchDB, Azure Cosmos DB
4. Graph
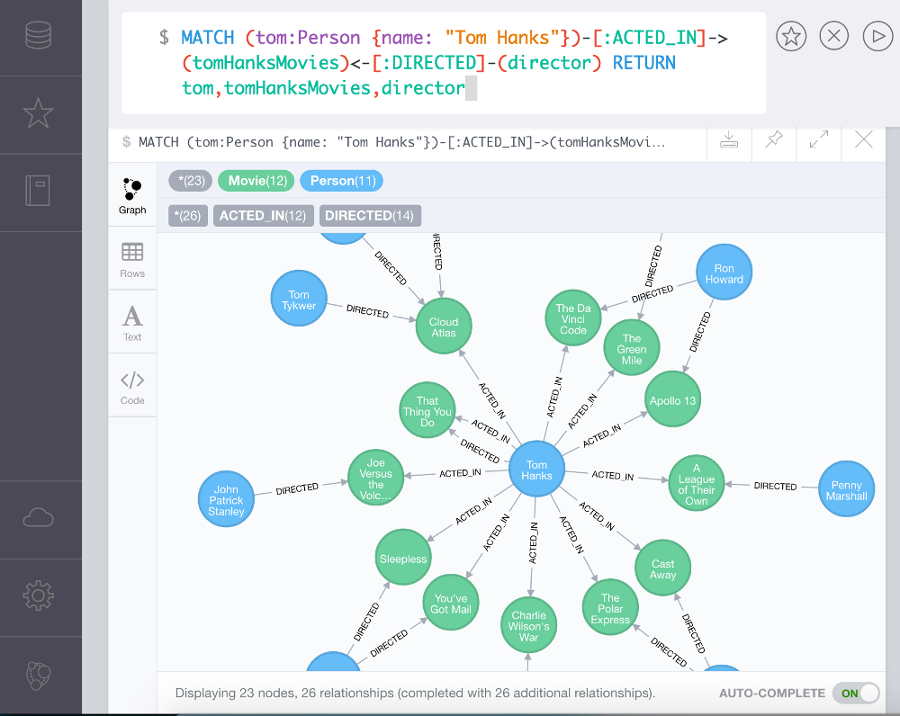
- 데이터를 노드로(그림에서 파란, 녹색 원) 표현하며 노드 사이의 관계를 엣지(그림에서 화살표)로 표현
- 일반적으로 RDBMS 보다 성능이 좋고 유연하며 유지보수에 용이한 것이 특징.
- Social network, Network diagrams 등에 사용할 수 있다.
- EX) Neo4j, BlazeGraph, OrientDB
- 아래에서 대표적으로 MongoDB, Redis 두 가지만 알아보겠습니다.
MongoDB
- 문서형 데이터베이스 중 가장 많이 쓰이는 데이터베이스이다.
- 몽고디비 실행 / 접속
- 몽고디비를 실행하기 전에 C:\data\db 폴더를 만들어야 합니다. 위 폴더를 만들지 않으면 몽고디비는 실행되지 않습니다. 폴더 생성 후
mongod명령어를 입력하면 몽고디비가 실행된다. - 실행 후 접속하기 위해서는
mongo명령어를 사용한다. - 만약 몽고디비를 실행할 때
mongod --auth로 실행을 하면,mongo admin -u [ID] -p [PW]처럼 옵션을 사용하여 접속해야 한다. - 위처럼 아이디 패스워드로 접속하려면 DB에 계정이 있어야 한다.
> use admin
> db.createUser({ user: 'ID', pwd: 'PW', roles: ['root'] })- DB 생성하기
use [DB 이름]명령어를 사용하면 mongo shell 에서 사용하는 데이터베이스를 바꿀 수 있다.show dbs명령어로 데이터베이스 목록을 확인할 수 있다. 만약, 데이터베이스가 없으면 새로 생성한다.
- 컬렉션 생성하기
- 몽고디비에서 컬렉션은 RDBMS에서 테이블과 같다.
- 컬렉션을 생성하는 명령어는
db.createCollection('collection 이름')이다. - 현재 컬렉션의 목록을 확인하는 명령어는
show collections이다.
- 컬렉션에 데이터 생성
db.collection.save({ name: 'kim', age: 26})처럼 생성이 가능하다.- 몽고디비 4.2 버전부터 위의 save()를 지원하지만, 공식문서에서는 insertOne(), insertMany() 를 권장하고 있다.
- 데이터 읽기
- 조회 명령어는
db.collection.find(query, projection)를 사용한다. query에는 조건, projection 에는 조회할 컬럼을 입력한다. db.collection.use({ age: {>: 26}}, { _id: 0, name: 1})처럼 조회한다.- query에는 특수 연산자를 사용한다.
- 특수 연산자 종류
- &eq : 같음
- > : 초과
- >e : 이상
- &in : 전달할 배열 요소 중 하나
- < : 미만
- <e: 이하
- &ne: 같지 않음
- &nin: 전달할 배열 요소 중에 없거나 필드가 존재하지 않을 때 조회
- projection에 조회할 필드를 전달 할 때에 0은 조회를 하지 않고, 1은 조회를 한다는 뜻이다.
- 데이터 수정
db.collection.update(query, update, options)명령어로 수정한다.db.collection.update({ name: 'kim'}, {&set: { age: 30}})이와 같이 name이 kim 인 값의 age 값을 30으로 바꿀 수 있다.- 여기서 &set 특수 연산자를 사용하지 않으면, 이 데이터 자체가 바뀐다.
- 데이터 삭제
db.collection.remove({ name: 'kim'})명령어를 사용한다.
Redis
- Key-Value 데이터베이스 중 가장 많이 쓰이며, 데이터베이스, 캐시, 메세지브로커로 사용되여 인메모리 데이터 구조를 가진다.
- 캐시 서버
- 데이터베이스는 데이터를 물리 디스크에 직접 쓰기 때문에 서버에 문제가 발생하여 다운되더라도 데이터가 손실되지 않는다. 하지만 매번 디스크에 접근해야 하기 때문에 사용자가 많아 질수록 부하가 많아져서 느려질 수 있다.
- 사용자가 늘어나면 데이터베이스가 과부하 될 수 있기 때문에 캐시 서버를 도입하여 사용한다. 이때 캐시 서버로 이용할 수 있는 것이 Redis 이다.
- 캐시는 한 번 읽어온 데이터를 임의의 공간에 저장하여 다음에 읽을 떄는 빠르게 결과 값을 받을 수 있도록 도와주는 공간이다.
- 같은 요청이 여러 번 들어오는 경우 매번 데이터베이스를 거치는 것이 아니라 캐시 서버에서 첫 번쨰 요청 이후 저장된 결과 값을 바로 내려주기 떄문에 데이터베이스의 부하를 줄이고 서비스의 속도도 느려지지 않는 장점이 있다.
- 캐시 서버에는 Look Aside Cache 패턴, Write Back 패턴이 있다.
- Look Aside Cache
- 클라이언트가 데이터를 요청'
- 웹서버는 데이터가 존재하는지 캐시 서버에 먼저 확인
- 캐시 서버에 데이터가 있으면 DB에 데이터를 조회하지 않고, 캐시 서버에 있는 결과 값을 클라이언트에게 바로 반환 (Cache Hit)
- 캐시 서버에 데이터가 없으면 DB에 데이터를 조회하여 캐시 서버에 저장하고 결과 값을 클라이언트에게 반환 (Cache Miss)
- Write Back
- 웹 서버는 모든 데이터를 캐시 서버에 저장
- 캐시 서버에 특정 시간 동안 데이터가 저장됨
- 캐시 서버에 있는 데이터를 DB에 저장
- DB에 저장된 캐시 서버의 데이터를 삭제
- INSERT 쿼리를 한 번씩 500번 날리는 것보다 INSERT 쿼리 500개를 붙여서 한 번에 날리는 것이 더 효율적이라는 원리.
- 이 방식은 들어오는 데이터들이 저장되기 전에 메모리 공간에 머무르는데 이때 서버가 다운되면 데이터가 손실될 수 있다.
- Look Aside Cache
- Redis 특징
- Key-Value 구조이기 때문에 쿼리를 사용할 필요가 없다.
- 데이터를 디스크에 쓰는 구조가 아니라 메모리에서 데이트를 처리하기 때문에 속도가 빠르다.
- String, Lists, Sets, Sorted Sets, Hashes 자료 구조를 지원합니다.
- String : 가장 일반적인 key-value 구조의 형태
- Sets : String의 집합이다. 여러 개의 값을 하나의 value에 넣을 수 있다. 포스트의 태깅 같은 곳에 사용될 수 있다.
- Sorted Sets : 중복된 데이터를 담지 않는 Set 구조에 정렬 Sort를 적용한 구조로 랭킹 보드 서버 같은 구현에 사용된다.
- Lists : Array 형식의 데이터 구조이다. List 를 사용하면 처음과 끝에 데이터를 넣고 빼는건 빠르지만 중간에 데이터를 삽입하거나 삭제하는 것은 어렵다.
- Single Threaded 이다.
- 한 번에 하나의 명령만 처리할 수 있다. 그래서 중간에 처리 시간이 긴 명령어가 들어오면 그 뒤에 명령어들은 모두 앞에 명령어가 처리될 때까지 기다려야한다. -> get, set 명령어는 매우 빨라서 상관이 없다.
- 주의할 점
- 서버에 장애가 발생했을 경우 그에 대한 운영 플랜이 필요하다.
- 인메모리 데이터베이스의 특정상, 서버에 장애가 발생했을 경우 데이터 유실이 발생하 수 있기 때문에
- 메모리 관리가 중요하다.
- 싱글 스레드의 특성상, 한 번에 하나의 명령어만 가능해서 명령어 관리가 필요하다.
- 서버에 장애가 발생했을 경우 그에 대한 운영 플랜이 필요하다.
- Redis 자세한 정보는 아래 링크를 참고하시면 됩니다.
https://wildeveloperetrain.tistory.com/32
다음 게시글 DB 추가 정보
https://hoozy.tistory.com/entry/%EB%B0%B1%EC%97%94%EB%93%9C-DB-%EC%B6%94%EA%B0%80-%EC%A0%95%EB%B3%B4
[백엔드] DB 추가 정보
이전 게시글 NoSQL(비관계형) DB https://hoozy.tistory.com/entry/%EB%B0%B1%EC%97%94%EB%93%9C-NoSQL%EB%B9%84%EA%B4%80%EA%B3%84%ED%98%95-DB 카테고리 : 데이터베이스 ORM 객체-관계 매핑의 약자로, 객체라는 개념을 구현한 클
hoozy.tistory.com
참고 자료
https://velog.io/@alicesykim95/Oracle%EA%B3%BC-MySQL%EC%9D%98-%EC%B0%A8%EC%9D%B4%EC%A0%90
https://wildeveloperetrain.tistory.com/21
https://code-lab1.tistory.com/53
https://mantaray.tistory.com/38
https://velog.io/@eogns1208/%EB%AA%BD%EA%B3%A0%EB%94%94%EB%B9%84-%EC%82%AC%EC%9A%A9%EB%B2%95
'CS > 데이터베이스' 카테고리의 다른 글
| [백엔드] DB 추가 정보 (0) | 2023.04.03 |
|---|---|
| [백엔드] 관계형 DB (0) | 2023.04.02 |

댓글