이전 게시글 운영 체제 1
https://hoozy.tistory.com/entry/%EB%B0%B1%EC%97%94%EB%93%9C-%EC%9A%B4%EC%98%81-%EC%B2%B4%EC%A0%9C-1
[백엔드] 운영 체제 1
이전 게시글 GIT / GITHUB https://hoozy.tistory.com/entry/GIT-GITHUB 카테고리 : 운영 체제 터미널이란 유닉스 기반의 대형 컴퓨터에서 사용자들이 컴퓨터에 접속하기 위해 사용했던 단말기로 요즘에는 컴퓨
hoozy.tistory.com
카테고리 : 운영 체제
프로세스 간 통신
- 프로세스들 간의 의사소통하는 것을 IPC라고 한다. 이는 서로 다른 프로세스가 데이터를 주고 받을 수 있다는 것을 뜻하며, 동시에 접근 가능한 메모리 즉, 프로세스들이 공유하는 메모리가 필요하다는 것이다.
- 따라서 컴퓨터 내부에서 효율적으로 정보를 주고 받기 위한 통신의 일종이라고 생각하면되고, 인터넷 통신을 IPC의 확장으로 이해할 수 있다.
- 프로세스간의 통신을 위해 '파이프'와 같은 개념이 등장하게 되었다.
- 프로세스 간 통신과 스레드 간 통신의 차이
- 프로세스 : 생성되면서 PC를 포함하여 메모리 공간 등을 복사하여 별도의 자원을 할당
- 스레드 : 메모리 공간과 자원을 공유한다.
- 따라서 프로세스는 통신할 수 있는 공간이 없기 때문에 통신을 위한 별도의 공간을 만들어주어야 하기 때문에 스레드 간 통신보다 어렵다.
- 이를 위해서 커널 영역에서 IPC라는 내부 프로세스간 통신을 제공하게 되고, 프로세스는 커널이 제공하는 IPC 설비를 이용해서 프로세스간 통신을 할 수 있다.
종류
- 공유 메모리
- 공유 메모리가 데이터 자체를 공유하도록 지원하는 설비. 프로세스간 메모리 영역을 공유해서 사용할 수 있도록 허용한다.
- 프로세스가 공유 메모리 할당을 커널에 요청하면 커널은 해당 프로세스에 메모리 공간을 할당한다. 이후 어떤 프로세스건 해당 메모리 영역에 접근할 수 있다.
- 공유 메모리가 각 프로세스에게 첨부하는 방식으로 작동하게 된다.
- 각 프로세스가 메모리 영역에 첨부됨
- 프로세스간 Read, Write를 모두 필요로 할 때 사용된다.
- 대량의 정보를 다수의 프로세스에게 배포 가능하다.
- 중개자 없이 곧바로 메모리에 접근할 수 있기 때문에 모든 IPC 중에서 가장 빠르게 작동할 수 있다.
- 파이프
- 통신을 위한 메모리 공간(버퍼)을 생성하여 프로세스가 데이터를 주고 받게끔 한다.
- 익명 파이프
- 일반적인 파이프
- 통신할 프로세스가 명확하게 알 수 있는 경우 사용
- 부모-자식 이나 형제 프로세스 간 통신에 사용
- 외부 프로세스에서 사용할 수 없다.
- 파이프는 두 개의 프로세스를 연결하고, 하나의 프로세스는 데이터를 쓰기만, 다른 하나는 읽기만 할 수 있다. 한 쪽 방향으로만 통신이 가능한 특징 때문에 반이중 통신이라고 부르기도 한다.
- 송/수신을 모두 하기 원한다면 두 개의 파이프를 만들어야 가능하다.
- 간단하게 사용할 수 있다. -> PIPE 함수로 생성
- 단점
- 반이중 통신 -> 프로세스가 읽기와 쓰기 통신을 모두 해야한다면, 파이프 두 개를 만들어야 하므로 구현이 복잡해진다.
- 전이중 통신을 고려해야될 상황이라면 낭비가 심하기 때문에 좋은 선택이 아니다.
- 네임드 파이프
- 전혀 모르는 상태의 프로세스들 사이의 통신에 사용
- 익명 파이프의 확장된 상태로 부모 프로세스와 무관한 다른 프로세스도 통신 가능
- 프로세스 통신을 위해 이름이 있는 파일을 사용하기 때문에 가능하다.
- FIFO라는 특수 파일을 이용해 서로 관련 없는 프로세스 간 통신에 사용.
- 외부 프로세스와 통신 가능하다.
- mkfifo or mknod 함수로 생성.
- 단점
- 반이중 통신 -> 전이중 통신을 위해서는 익명 파이프처럼 두 개를 만들어야 가능하다.
- 전혀 모르는 상태의 프로세스들 사이의 통신에 사용
- 소켓
- 유닉스 도메인 소켓 또는 IPC 소켓은 동일한 호스트 운영 체제에서 실행되는 프로세스간 데이터를 교환하기 위한 데이터 통신 엔드 포인트이다.
- 네트워크 소켓 통신을 통해 데이터를 공유한다.
- 데이터 교환을 위해 양쪽 PC에서 각각 임의의 포트를 정하고 해당 포트 간의 대화를 통해 데이터를 주고 받는 방식이다.
- 이 때 각각 PC의 포트를 담당하는 소켓은 각각 하나의 프로세스이다.
- 해당 프로세스는 임의의 포트를 맡아 데이터를 송수신 하는 역할을 진행하는 프로세스인 것이다.
- 각각의 PC에서 프로세스를 통해 타 PC 포트에 연결하라는 명령을 보내게 되면 두 프로세스는 서로 확인 과정을 거쳐 연결을 진행하고 연결 후 마치 파이프와 같이 1:1 로 데이터를 주고 받는 방식이다.
- 클라이언트와 서버가 소켓을 통해서 통신하는 구조로, 원격에서 프로세스 간 데이터를 공유할 때 사용.
- 전이중(쌍방향) 통신이 가능하다.
- 서버/클라이언트 환경을 구축하는데 용이하다.
- 서버(bind, listen, accept), 클라이언트(connect)
- 중대형 애플리케이션에서 주로 사용한다.
- 네트워크 소켓 통신을 통해 데이터를 공유한다.
- 유닉스 도메인 소켓 또는 IPC 소켓은 동일한 호스트 운영 체제에서 실행되는 프로세스간 데이터를 교환하기 위한 데이터 통신 엔드 포인트이다.
- 메시지 큐
- 입출력 방식은 네임드 파이프와 동일하다.
- 차이점
- 메시지 큐는 파이프처럼 데이터의 흐름이 아니라 메모리 공간이다 -> 메모리를 사용한 파이프
- 파이프나 FIFO와 달리 다수의 프로세스간 메시지를 전달할 수 있다.
- 사용할 데이터에 번호를 붙이면서 여러 프로세스가 동시에 데이터를 쉽게 다룰 수 있다.
- 메시지 접근을 위해서는 키가 필요하다.
- 메모리 맵
- 공유 메모리처럼 메모리를 공유해준다.
- 열린 파일을 메모리에 매핑시켜서 공유하는 방식 -> 공유 매개체가 파일 + 메모리
- 주로 파일로 대용량 데이터를 공유해야 할 때 사용
- 파일 IO가 느릴 때 사용하면 좋다
- 대부분 운영 체제에서는 프로세스를 실행할 때 실행 파일의 각 세그먼트를 메모리에 사상하기 위해 메모리 맵 파일을 이용한다.
- 메모리 맵 파일은 파일의 크기를 바꿀 수는 없으며, 메모리 맵 파일을 사용하기 이전 또는 이후에만 파일의 크기를 바꿀 수 있다.
- RPC (Remote Procedure Call)
- 분산 네트워크 망에서 많이 사용되는 방식
- 별도의 원격 제어를 위한 코딩 없이 다른 주소 공간에서 함수나 프로시저를 실행할 수 있게 하는 프로세스 간 통신 기술
- 즉 원격 프로시저 호출을 이용하면 프로그래머는 함수가 실행 프로그램에 로컬 위치에 있든 원격 위치에 있든 동일한 코드를 이용할 수 있다.
- 해당 방법은 분리된 PC에 저장된 데이터를 마치 내 PC에 존재하는 것처럼 데이터를 가져와 사용하는 통신 방법
- 스텁(Stub)을 통해서 마치 자신의 디스크에 존재하는 것처럼 착각을 일으켜 사용하는 방식
- 스텁 : 리눅스에서 공유 라이브러리의 일부분 중 하나
- 프로시저 : 루틴, 서브루틴, 함수와 같은 뜻으로 사용되며 하나의 프로시저는 특정 작업을 수행하기 위한 프로그램의 일부이다. 또는 어떤 행동을 수행하기 위한 일련의 작업이다.
- 이러한 IPC 통신에서 프로세스 간 데이터를 동기화하고 보호하기 위해 세마포어 와 뮤텍스를 사용한다. -> 공유된 자원에 한 번에 하나의 프로세스만 접근시킬 때
- 세마포어
- 위의 다른 IPC 설비들이 대부분 프로세스 간 메시지 전송을 목적으로 하는 것에 반해, 세마포어는 프로세스간 데이터를 동기화하고 보호하는데 목적을 둔다.
- 공유된 자원에 여러 개의 프로세스가 동시에 접근하면 안되며, 한 번에 하나의 프로세스만 접근 가능하도록 할 때 사용.
- 뮤텍스
- 키에 해당하는 오브젝트가 있으며, 이 오브젝트를 소유한 (스레드, 프로세스) 만이 공유자원에 접근할 수 있다.
- 키는 하나고, 스레드나 프로세스가 공유자원을 사용하고 있으면, 다른 스레드나 프로세스가 키가 없기 때문에 공유자원을 사용못한다.
- 세마포어
프로세스 간 통신 정리
| IPC 종류 | 파이프 | 네임드 파이프 | 메시지 큐 | 공유 메모리 | 메모리 맵 | 소켓 |
|---|---|---|---|---|---|---|
| 사용 시기 | 부모 자식(형제) 간 단방향 통신시 | 다른 프로세스와 단방향 통신시 | 다른 프로세스와 단방향 통신시 | 다른 프로세스와 양방향 통신시 | 다른 프로세스와 양방향 통신시 | 다른 시스템간 양방향 통신시 |
| 공유 매개체 | 파일 | 파일 | 메모리 | 메모리 | 파일 + 메모리 | 소켓 |
| 통신 단위 | 스트림 | 스트림 | 구조체 | 구조체 | 페이지 | 스트림 |
| 통신 방향 | 단방향 | 단방향 | 단방향 | 양방향 | 양방향 | 양방향 |
| 통신 가능 범위 | 동일 시스템 | 동일 시스템 | 동일 시스템 | 동일 시스템 | 동일 시스템 | 동일 + 외부 시스템 |
I/O 관리
입출력 시스템
- 컴퓨터의 주요한 두 가지 작업은 연산 작업과 입출력 작업이다.
- 대부분의 경우에 연산 작업보다는 입출력 작업이 중요한데, 예를 들어 우리가 인터넷 서핑을 하거나 문서 작업을 할 때 대부분은 컴퓨터 내의 저장된 파일을 열거나 작성하는 경우가 많기 때문이다.
- 마우스, 키보드, 모니터와 같은 다양한 장치들이 컴퓨터와 잘 동작하게 하려면 둘 사이에 공통된 인터페이스가 존재해야한다.
- 이때 컴퓨터와 하드웨어 장치 사이의 공통된 인터페이스 역할을 수행하는 것이 입출력 관리의 핵심이다.
- 이런 인터페이스의 표준화는 입출력 관리에서 매우 중요하다.
- 운영 체제 커널이 이렇게 다양한 입출력 장치들의 차이를 가려주기 위해서 장치 구동기 모듈을 사용한다.
- 장치 구동기 : 모든 하드웨어를 일관된 인터페이스로 표현해 주며 이런 인터페이스를 그보다 상위층인 커널의 입출력 서브시스템에 제공해준다.
입출력 하드웨어의 구성
- 하드웨어 장치는 케이블을 통하거나, 무선으로 신호를 보내어 컴퓨터와 통신한다.
- 이 때 포트를 통해 컴퓨터에 접속하는데, 하드웨어 장치의 또 다른 구성요소는 제어기이다.
- 제어기 : 포트나 입출력 장치를 제어하는 전자회로의 집합체이며, 많은 입출력 장치는 제어기를 내장하고 있다.
- 모든 제어기는 레지스터를 가지고, 컴퓨터의 프로세스는 제어기 레지스터에 bit pattern 을 쓰거나 읽음으로서 입출력을 실행한다.
입출력 하드웨어 동작
폴링
- 장치 제어기의 레지스터에는 busy bit가 있다.
- busy bit : 현재 장치가 사용 가능한 상태인지 다른 작업을 처리하는 중이어서 사용이 불가능한 상태 인지를 나타내는 bit 이다.
- 1 : 제어기가 바쁜 경우 (제어기 작업중)
- 0 : 제어기가 준비 중인 경우
- 컴퓨터는 장치가 사용중인지를 알기 위해 주기적으로 busy bit 을 검사해야 하는데 이 과정을 폴링이라고 한다.
- 폴링 자체는 컴퓨터 자원이 많이 소요되지 않지만 장치가 준비하는 시간이 길어진 경우 매우 비효율적인 단점이 있다.
- 이런 경우 제어기가 자신의 상태가 바뀔 때 컴퓨터에 통보해주는 방식으로 비효율을 막을 수 있다.
- 이때 발생시키는 신호를 인터럽트라고 한다.
인터럽트
- CPU가 프로그램을 실행하고 있을 때 입출력 하드웨어 등의 장치나 예외 상황이 발생하여 처리가 필요할 경우 CPU에게 알려 처리할 수 있도록 하는 것을 말한다.
- CPU는 인터럽트 요청 라인이라는 선을 가지는데 CPU는 매번 명령어를 끝내고 다음 명령어를 수행하기 전에 이 선을 검사한다.
- 만약 입출력 장치의 준비가 완료되어서 인터럽트 요청 라인에 신호를 보내면, CPU는 인터럽트를 확인하고 인터럽트 핸들러를 실행한다.
- 인터럽트 핸들러 : 입출력 장치를 서비스함으로서 인터럽트를 처리한다.
- CPU는 인터럽트 발생 시 직전 작업 상태를 저장해두고 인터럽트를 처리한다.
- 인터럽트 처리가 완료된 이후에는 인터럽트가 발생하기 전의 상태로 복구시켜 중단되었던 작업을 재개한다.
작업 순서
- 사용자가 키보드를 사용해 입력하면 키보드 컨트롤러가 인터럽트를 발생, CPU에게 알림
- CPU는 현재 수행 중이던 작업의 상태를 저장, 인터럽트 요청을 처리하기 위해 운영 체제내에 정의된 키보드 인터럽트 처리 루틴을 찾음
- 키보드 인터럽트 처리 루팅을 실행, 완료.
- 인터럽트 처리가 끝나면 인터럽트가 발생하기 직전 상태를 복구시켜 중단되었던 작업을 재개.
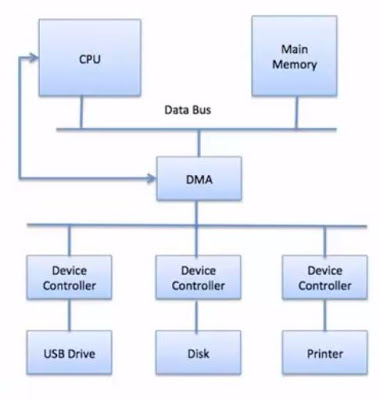
직접 메모리 접근 (Direct Memory Access)
- CPU를 사용하여 디스크와 같은 대용량 입출력 장치의 데이터를 읽으면 CPU 사용량이 매우 높아져 컴퓨터 성능이 심각하게 저하되는 문제가 있다.
- CPU가 매번 바이트 전송을 제어하는 것은 엄청난 낭비이다.
- PIO : CPU가 1 BYTE씩 옮기는 입출력 방식
- 많은 컴퓨터들의 CPU의 낭비를 막기 위해서 PIO를 DMA(Direct Memory Access) 제어기라고 불리는 특수 프로세서에게 위임하여 CPU의 일을 줄여준다.
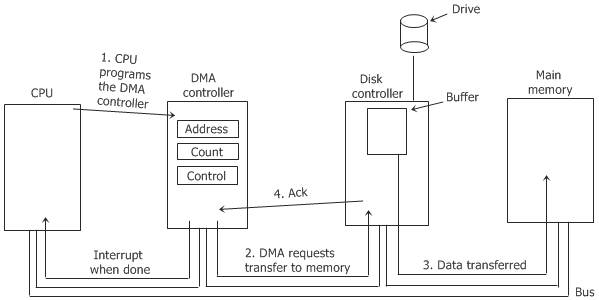
- 컴퓨터는 메모리에 DMA 명령 블록을 쓴다.
- 이 블록에는 전송항 데이터가 있는 곳의 포인터와 전송할 장소에 대한 포인터, 전송할 바이트 수가 기록된다.
- CPU는 DMA 명령 블록의 주소를 DMA에게 알려주고 자신의 다른 일을 처리한다.
- DMA는 CPU의 도움 없이 자신이 직접 버스를 통해 DMA 명령 블록에 접근하여 입출력을 실행한다.
작업 순서
- CPU가 입출력 요청을 보냄
- DMA 제어기의 레지스터에 주소와 전송 길이가 저장
- DMA 제어기는 한 블록의 입출력 동작을 수행, 그 동안 CPU는 다른 작업을 한다.
- 입출력 동작 완료 시 DMA 제어기는 CPU에게 완료했다는 인터럽트를 보냄.
네트워킹
- 네트워킹 : 서로 데이터를 교환하고 리소스를 공유할 수 있는 상호 연결된 컴퓨팅 디바이스.
- 이러한 네트워크 디바이스는 통신 프로토콜이라고 하는 규칙 시스템을 사용하여 물리적 또는 무선 기술을 통해 정보를 전송한다.
- 작동하는 법
- 노드와 링크는 컴퓨터 네트워킹의 기본 빌딩 블록이다.
- 노드 : 모뎀, 허브 또는 스위치와 같은 데이터 통신 장치 또는 여러 대의 컴퓨터 및 프린터와 같은 데이터 단말 장치일 수 있다.
- 링크 : 두 노드를 연결하는 전송 매체를 의미하고, 케이블 와이어나 광섬유와 같은 물리적이거나 무선 네트워크에서 사용하는 여유 공간일 수 있다.
- 작동하는 컴퓨터 네트워크에서 노드는 링크를 통해 전자 데이터를 전송하고 수신하는 방법을 정의하는 일련의 규칙 또는 프로토콜을 따른다.
- 컴퓨티 네트워크 아키텍처는 이러한 물리적 및 논리적 구성 요소의 디자인을 정의하며, 네트워크의 물리적 구성 요소, 기능 조직, 프로토콜 및 절차에 대한 사양을 제공한다.
- 노드와 링크는 컴퓨터 네트워킹의 기본 빌딩 블록이다.
- 현대적 컴퓨터 네트워크는 아래와 같은 일을 수행할 수 있다.
- 가상으로 운영
- 기본 물리적 네트워크 인프라는 논리적으로 분할되어 여러 오버레이네트워크를 생성할 수 있다. 오버레이 컴퓨터 네트워크에서 노드는 가상으로 연결되며 여러 물리적 경로를 통해 노드 간에 데이터를 전송할 수 있다.
- 예를 들면, 많은 기업 네트워크가 인터넷에 중첩되어 있다.
- 대규모 통합
- 물리적으로 분산된 컴퓨터 네트워크를 연결할 수 있다. 이러한 서비스는 자동화와 모니터링을 통해 네트워크 기능을 최적화하여 하나의 대규모 고성능 네트워크를 생성할 수 있다.
- 네트워크 서비스는 수요에 따라 확장하거나 축소할 수 있다.
- 변화하는 상황에 신속하게 대응
- 많은 컴퓨터 네트워크가 소프트웨어로 정의합니다. 디지털 인터페이스를 사용하여 중앙에서 트래픽을 라우팅하고 제어할 수 있다.
- 이러한 컴퓨터 네트워크는 가상 트래픽 관리를 지원한다.
- 데이터 보안 제공
- 모든 네트워킹 솔루션에는 암호화 및 액세스 제어와 같은 기본 제공 보안 기능이 있다.
- 바이러스 백신 소프트웨어, 방화벽 및 맬웨어 방지 프로그램과 같은 서드 파티 솔루션을 통합하여 네트워크의 보안을 강화할 수 있다.
- 가상으로 운영
컴퓨터 네트워크 아키텍처의 유형
- 클라이언트 - 서버 아키텍처
- 이러한 유형의 컴퓨터 네트워크에서 노드는 서버 또는 클라이언트일 수 있고, 서버 노드는 메모리, 처리 능력 또는 데이터와 같은 리소스를 클라이언트 노드에 제공한다.
- 서버 노드는 클라이언트 노드 동작을 관리할 수 있으며 클라이언트는 서로 통신할 수 있지만, 리소스를 공유하지는 않는다.
- 예를 들어, 기업 네트워크의 일부 컴퓨터 디바이스는 데이터 및 구성 설정을 저장한다. 이러한 디바이스는 네트워크의 서버입니다. 클라이언트는 서버 시스템에 요청하여 이 데이터에 액세스할 수 있다.
- P2P 아키텍처
- P2P(피어 투 피어) 아키텍처에서 연결된 컴퓨터는 동일한 권한을 갖는다.
- 조정을 위한 중앙 서버가 없고, 컴퓨터 네트워크의 각 디바이스는 클라이언트 또는 서버 역할을 할 수 있다.
- 각 피어는 전체 컴퓨터 네트워크와 메모리, 처리 능력 등의 몇 가지 리소스를 공유할 수 있다.
- 예를 들어, 일부 회사는 P2P 아키텍처를 사용하여 여러 디지털 디바이스에서 3D 그래픽 렌더링과 같은 메모리 소비 응용 프로그램을 호스팅합니다.
기업 컴퓨테 네트워크 유형
- LAN (Local Area Network)
- 크기와 지역이 제한된 상호 연결된 시스템으로, 대개 단일 사무실이나 건물 내에서 컴퓨터와 디바이스를 연결한다.
- 소규모 회사에서 사용되거나 소규모 프로토타이핑을 위한 테스트 네트워크로 사용된다
- WAN (Wide Area Network)
- 건물, 도시 및 국가에 걸쳐 있는 기업 네트워크이다.
- LAN은 근거리 내에서 더 빠른 속도로 데이터를 전송하는데 사용되지만, WAN은 안전하고 신뢰할 수 있는 장거리 통신용으로 쓰인다.
- SD-WAN 또는 소프트웨어 정의 WAN은 소프트웨어 기술로 제어되는 가상 WAN 아키텍처이다.
- 보안 및 서비스 품질을 희생하지 않고, 애플리케이션 수준에서 제어할 수 있는 더 유연하고 신뢰할 수 있는 연결 서비스를 제공한다.
- 서비스 제공업체 네트워크
- 고객은 공급자로부터 네트워크 용량과 기능을 임대할 수 있다.
- 네트워크 서비스 제공업체는 통신 회사, 데이터 캐리어, 무선 통신 제공업체, 인터넷 서비스 제공업체 및 고속 인터넷 액세스를 제공하는 케이블 텔레비전 운영자로 구성될 수 있다.
- 클라우드 네트워크
- 클라우드 기반 서비스가 제공하는 인프라가 있는 WAN이라고 할 수 있다.
- 조직의 네트워크 기능 및 리소스의 일부 또는 전체의 퍼블릭 또는 프라이빗 클라우드 플랫폼에서 호스팅되며 온디맨드 방식으로 제공된다.
- 이러한 네트워크 리소스에는 가상 라우터, 방화벽, 대역폭 및 네트워크 관리 소프트웨어 포함될 수 있으며 필요에 따라 다른 도구와 기능을 사용할 수 있다.
스레드 및 동시성
요약
- 스레드는 CPU 사용의 기본 단위를 나타내며 동일한 프로세스에 속하는 스레드는 코드 및 데이터를 포함하여 많은 프로세스 자원을 공유한다.
- 다중 스레드 응용프로그램에는 응답성, 자원 공유, 경제성, 확장성 이라는 4가지 주요 이점이 있다.
- 여러 스레드가 진행 중인 경우 동시성이 존재하는 반면에, 여러 스레드가 동시에 진행 중인 경우 병렬성이 존재한다. 단일 CPU가 있는 시스템에서는 오로지 동시성만 가능하고, 병렬성은 여러 CPU를 제공하는 다중 코어 시스템이 필요하다.
- 다중 스레드 응용프로그램을 설계하는 데 몇가지 도전과제가 있다. 작업 분할 및 균형 조정, 서로 다른 스레드 간에 데이터 분할 및 데이터 종속성 식별이 포함된다. 마지막으로, 다중 스레드 프로그래믄 테스트 및 디버깅에 특히 어려움이 있다.
- 사용자 응용 프로그램은 사용자 수준 스레드를 생성하며, 이 스레드는 궁극적으로 CPU에서 실행되도록 커널 스레드에 매핑되어야 한다. 다대일 모델은 많은 사용자 수준 스레드를 하나의 커널 스레드에 매핑한다. 다른 접근법으로는 일대일 및 다대다 모델이 있고, 현재는 일대일 모델이 대부분에 쓰인다.
- 스레드는 비동기 또는 지연 취소를 사용하여 종료될 수 있다. 비동기 취소는 스레드가 업데이트를 수행하는 중이라도 스레드를 즉시 중지한다. 지연 취소는 스레드에 종료해야 한다고 통지하지만 스레드는 질서 정연하게 종료된다. 대부분의 경우 비동기 종료보다 지연 취소가 선호된다.
- 자세한 건 아래 게시글에 있습니다.
https://hoozy.tistory.com/entry/%EB%B0%B1%EC%97%94%EB%93%9C-%EC%8A%A4%EB%A0%88%EB%93%9C
프로세스 관리
- 운영체제는 자원을 효율적으로 할당해 주는 역할을 한다. 이를 위해서는 각 프로그램이 메모리의 어디에 적재되는지, 어떤 프로세스가 먼저 실행되어야 하는지의 관리가 필요하다.
- 프로그램과 프로세스의 차이점
- 프로그램 : 하드디스크에 저장된 명령어들의 집합. 프로그램의 상태(메모리에 적재되지 않은 상태)에서는 아무 일도 수행하지 않는다.
- 프로세스 : 프로그램이 메모리에 적재된 상태. 즉 프로세스는 프로그램의 인스턴스라고도 할 수 있다.
- 프로세스는 job, task라고도 불리며 실행중인 프로그램이라도고 한다. 프로세스의 code나 data, stack, program, counter, register등의 값이 프로세스 실행중에 계속 바뀌며 한 컴퓨터 내에서 여러 프로세스가 돌아갈 수 있다.
- 한 컴퓨터 내에 여러 프로세스가 돌아가는 것을 멀티프로그래밍이라고 하며 cpu 효율을 높이기 위해 고안되었다.
프로세스의 상태
- new : 프로세스가 메인 메모리로 적재된 상태
- ready : 프로세스가 실행될 모든 준비가 끝난 상태
- running : CPU가 실제로 프로세스를 실행한 상태
- waiting : 프로세스가 대기하는 상태. 프로세스에 입출력 등의 명령이 있으면 이 프로세스는 입출력이 동작하는 동안 waiting함
- terminated : 프로세스가 종료된 상태.
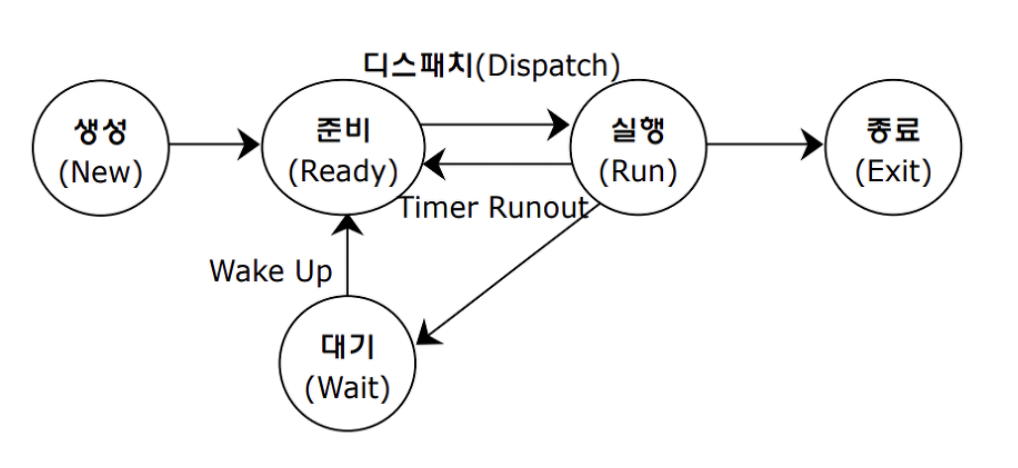
- 프로그램이 메모리에 적재되어 프로세스가 생성(new)되었다.
- 프로세스가 실행될 모든 준비를 마쳤다(ready).
- CPU가 실제로 프로세스를 실행(run)하였다. 이 과정에서 어떤 프로세스를 실행할 것인지 결정하는 dispatch가 동작한다.
- 프로세스에서 입출력 명령이 있어 입출력이 동작하는 동안 프로세스는 대기(waiting)한다.
- 입출력이 끝난 프로세스가 CPU의 서비스를 받을 준비(waiting)를 한다. 이 과정은 wait 하다가 일어난 일이기에 wake up 과정이라고도 한다.
- 다시 CPU가 실제로 프로세스를 실행(run)한다. 이 과정에서도 dispatch가 수행된다.
- 만약 이 system이 Time Sharing System이고, 이 프로세스가 CPU 시간을 모두 소진했다면 다시 준비 상태로 올 수 있다.
- run의 상태에서 프로세스의 모든 명령어가 실행되었다면 이제 프로세스는 종료된다.
PCB
- 프로세스에 대한 모든 정보를 블럭 속에 저장하고 있으며, 한 개의 프로세스에 대해 한 개의 PCB가 배정된다.
- PCB 내부의 정보
- 프로세스 state(running, ready, waiting, ...), pc, registers, MMU info (base, limit), CPU time, 프로세스 id, list of open files, ...
Queue
- 프로그램의 메모리 적재 과정과 실행등에서 queue 라는 버퍼를 이용한다. 용량의 한계와 성능의 향상 때문에 queue를 이용한다.
Queue 종류
- 모든 Queue에는 PCB가 저장되어 있다.
- Job Queue
- 하드디스크에서 메모리로 프로그램이 적재될 때 바로 적재되지 못하기 때문에 queue에 잠시 대기하는 공간이다.
- 이는 프로그램은 많으나 메인 메모리의 용량이 작기 때문에 모든 프로그램이 한 번에 메인 메모리에 적재되지 못하고 순서를 기다려햐 하는 것이다.
- Job Queue에 올라온 job은 순서를 기다리며 메인 메모리에 올라올 때까지 대기한다.
- 보통 queue라면 FIFO 순서로 되지만, 이 Job Queue에서는 job scheduler(= long term schedular)를 통해 어떤 job을 먼저 적재할지 판단한다.
- long term schedular인 이유
- 일어나는 빈도가 적기 때문. 메모리로 프로그램이 적재되려면 메모리에 빈 공간이 있어야 하기 때문에 하나의 프로세스가 종료되어야 비로소 일어날 수 있다.
- long term schedular인 이유
- Ready Queue
- CPU 서비스를 받기 위해 프로세스가 대기하는 공간이다. CPU 개수의 한계 때문에 메모리로 올라온 모든 프로세스가 CPU의 서비스를 받을 수 없다. 따라서 Ready queue에 잠시 대기하고 CPU의 서비스를 기다리는 것이다.
- Ready Queue 또한 마찬가지로 cpu schedular(= short term schedular)를 통해 어떤 프로세스를 먼저 CPU 서비스를 받게 할 것인지 판단한다.
- short term schedular인 이유
- 일어나는 빈도가 잦다. Time Sharing System으로 인해 일정 시간이 지나면 CPU 서비스 받는 프로세스를 바꾸기 때문이다.
- short term schedular인 이유
- Device Queue
- 입출력 서비스를 받기 위해 프로세스가 대기하는 공간이다. 입출력은 시간이 오래 걸리기 때문에 입출력 명령을 호출한다고 해서 바로 받을 수 있는 것이 아니다. -> 앞서 다른 이가 호출한 입출력 명령이 있어 겹칠 수 있다.
- 따라서 Device Queue를 통해 입출력을 위한 공간을 마련한다.
- Device Schedular를 통해 어떤 프로세스가 먼저 입출력 서비스를 받게 할 것인지를 스케쥴링한다.
멀티 프로그래밍
- 한 프로세스의 일부가 실행된 뒤 다른 프로세스의 일부가 실행되는 식으로 진행되는데 이 텀이 매우 짧아 사용자의 입장에서는 동시에실행되는 것처럼 보인다.
- degree of multi programming : 메모리에 프로세스가 몇 개 올라와 있는지를 말한다.
- I/O bound vs cpu-bound process
- I/O bound 프로세스는 주로 I/O 작업을 하는 프로세스를 말하며, 워드 프로세스 등을 예로 든다.
- cpu-bound 프로세스는 주로 CPU를 사용하는 프로세스를 말하며, 일기예보 등 슈퍼컴퓨터를 사용하는 프로세스들이 여기에 속한다고 볼 수 있다.
- job schedular는 효율을 위해 I/O와 CPU BOUND 프로세스를 적절히 분배해 스케쥴링 해야 한다.
- Medium-term schedular
- long term 보단 빈도가 잦고, short term 보단 빈도가 덜하다.
- 이 스케쥴러는 프로세스들을 검사하여 장시간 이용되지 않은 프로세스들을 추출해 하드디스크로 옮기는(swap out)하는 역할을 한다.
- 일반적으로 하드디스크는 file system과 swap device로 이루어져 있어 장시간 사용되지 않는 프로세스를 이 하드디스크로 옮기고, 이 프로세스가 나중에 사용되려고 하면 다시 메모리로 옮기는(swap in)의 역할을 이 스케쥴러가 한다.
- 즉, OS의 프로세스 관리부서가 프로세스를 검사해서 swap in, swap out 할지 결정하는 스케쥴러이다.
- Context Switching (문맥 전환)
- CPU가 프로세스 1 돌다가 프로세스 2로 넘어가는 것을 뜻한다.
- schedular : 프로세스 한 개가 끝나고, 이후 어떤 프로세스를 실행할 것인지 결정.
- dispatcher : 스케쥴러가 선택한 프로세스를 실행하도록 레지스터 값을 바꾼다. 즉, 준비상태에서 실행상태로 바꾼다. 이전 프로세스의 정보를 프로세스 관리부서의 PCB 1에 저장하고, PCB 2 값을 복원한다. 즉 실행했던 프로세스 정보를 PCB에 저장, 실행할 프로세스 정보를 복원.
- Context Switching Overhead : context switching 부담. 효율을 높이기 위해 이 overhead를 최대한 줄여야한다.
다음 게시글 관계형 DB
https://hoozy.tistory.com/entry/%EB%B0%B1%EC%97%94%EB%93%9C-%EA%B4%80%EA%B3%84%ED%98%95-DB
[백엔드] 관계형 DB
이전 게시글 운영 체제 2 https://hoozy.tistory.com/entry/%EB%B0%B1%EC%97%94%EB%93%9C-%EC%9A%B4%EC%98%81-%EC%B2%B4%EC%A0%9C-2 카테고리 : 데이터베이스 관계형 데이터베이스란 행과 열로 이루어진 각각의 테이블을 고유
hoozy.tistory.com
참고 자료
https://dar0m.tistory.com/233
https://worthpreading.tistory.com/90
https://velog.io/@ragi/Back-end-%EC%9E%85%EC%B6%9C%EB%A0%A5IO-%EA%B4%80%EB%A6%AC
https://aws.amazon.com/ko/what-is/computer-networking/
https://dkswnkk.tistory.com/401?category=513905
https://velog.io/@yeunjoo121/%EC%9A%B4%EC%98%81%EC%B2%B4%EC%A0%9C-%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4-%EA%B4%80%EB%A6%AC
'CS > 운영 체제' 카테고리의 다른 글
| [백엔드] 리눅스 터미널 명령어 (0) | 2023.03.31 |
|---|---|
| [백엔드] 스레드 (0) | 2023.03.30 |
| [백엔드] JVM 메모리 관리 (0) | 2023.03.30 |
| [백엔드] 운영 체제 1 (0) | 2023.03.30 |


댓글